


Overview
Apple unveils Pico-Banana-400K officially, a groundbreaking real-image dataset featuring over 400,000 photorealistic visuals paired with precisely edited outputs and detailed text prompts. Designed to advance text-guided image editing, computer vision, and generative AI research, this dataset marks a major leap in Apple’s ongoing investment in machine learning innovation.
Unlike traditional synthetic datasets, Pico-Banana-400K showcases real-world image edits across multiple categories — from subtle lighting adjustments to complex object transformations. This diversity directly addresses one of AI’s biggest bottlenecks: the shortage of high-quality, real-image training data that has long constrained the performance of advanced models like GPT-4o, Gemini, and Stable Diffusion.
By opening up this research-only dataset, Apple is not only strengthening its AI research ecosystem but also fueling the next generation of photo-realistic image editing tools — paving the way for smarter, context-aware visual AI models that can understand and modify images with near-human precision.
What is Pico-Banana-400K?
Pico-Banana-400K is a large-scale text-guided image-editing dataset built from real photographs. Each dataset entry is a text–image–edit triplet: an original photo, a human-style edit instruction (text prompt), and the edited output image. The original images are drawn from the OpenImages collection (sources: GitHub / MacRumors).
Discover what’s coming next from Apple with the Apple 2026 roadmap leaks.
Key facts and structure
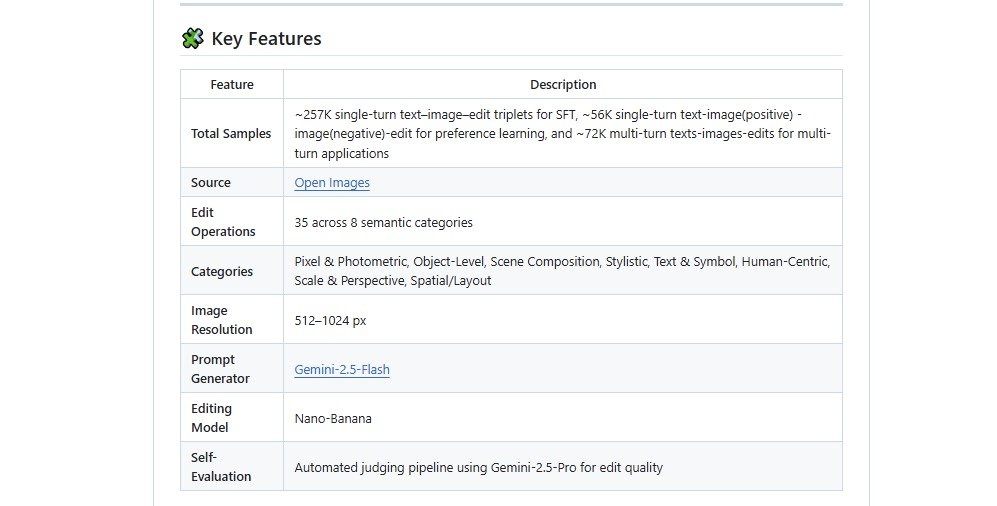
- Size: ~400,000 images paired with corresponding edits.
- Edit taxonomy: The dataset covers 35 distinct edit operations grouped into 8 major categories — for example:
- Color & tone adjustments (e.g., change a red car to blue)
- Object addition or removal (add a lamp, remove a person)
- Background replacement and scene changes
- Style transfer and artistic transformations (e.g., “make this look like a Pixar still”)
- Other complex geometric or semantic edits.
- Color & tone adjustments (e.g., change a red car to blue)
- Quality checks: Edit outputs and their quality were evaluated using large multimodal models (reported testing involved Google’s Gemini-2.5-Pro) to ensure robust edit examples. (sources: Geekflare / GitHub)
How the dataset is partitioned
Pico-Banana-400K ships with three focused subcollections to support different training regimes:
- ~257,000 single-step examples for supervised fine-tuning (SFT).
- ~56,000 preference pairs (successful vs. failed edits) to train reward models or preference learning.
- ~72,000 multi-step sequences showing chained edits — useful for teaching models how images evolve across multiple successive instructions.
Why this matters
Because entries include both successful and failed edits and multi-step edit sequences, the dataset is designed to teach models not just what a good edit looks like, but why it’s better — enabling better reward modeling, RLHF-style tuning, and more controlled text-to-edit generation.
Though Pico-Banana-400K is primarily a research resource (intended for non-commercial research use), models trained on it should translate into more capable consumer tools for photo apps, creative suites, and automated image workflows (source: MacRumors / Geekflare).
Who is Pico-Banana-400K for?
Pico-Banana-400K is primarily aimed at AI researchers, machine-learning engineers, and computer-vision teams who build and evaluate image-editing models. The dataset’s text–image–edit triplets and paired examples make it especially valuable for:
- Model training & fine-tuning (supervised fine-tuning / SFT) of photorealistic image-editing networks.
- Reward modeling and preference learning, thanks to the included successful vs. failed edit pairs that help train models to prefer higher-quality outputs.
- Multi-step editing workflows, where chained edit sequences teach systems to perform progressive changes across several instructions.
Beyond core research labs, app developers and product teams working on photo editors, creative suites, or automated imaging features can use models trained on this data as the backbone for next-gen user tools — provided they respect the dataset’s licensing. Creative professionals and UX teams will also find the dataset useful for prototyping advanced features like text-guided object removal, background replacement, and style transfer.
Important license note: Pico-Banana-400K is released for non-commercial, research-only use. That means academic projects, open research, and internal prototyping are allowed, but direct commercial deployment of the raw dataset is restricted. Organizations aiming to commercialize features should plan for licensed datasets or custom data-collection pipelines.
Why Apple Unveils Pico-Banana-400K Matters?
The core problem: training data gaps for image editing AI
Modern multimodal models (think GPT-4o or Gemini-class systems) have improved text-guided image editing dramatically, but their real-world performance is still bottlenecked by lack of high-quality, real-image training data. Many prior datasets are synthetic or limited in diversity, so models often learn on simplified examples that don’t reflect messy, real-world photos.
As a result, promising research struggles to translate into reliable consumer tools for photorealistic edits and complex transformations.
Real-world limitations: what goes wrong without real photos
When training data is synthetic or narrow, models suffer from domain shift — they perform well on curated test cases but fail on everyday images with occlusions, complex lighting, or subtle semantic context. That leads to brittle edits, unnatural color shifts, or incorrect object manipulations. In short: models learn the wrong shortcuts and can’t generalize to the variety of real photography used by creators and apps.
Apple’s approach: building a higher-quality training foundation
Pico-Banana-400K tackles these gaps by providing large-scale, photorealistic text–image–edit triplets, including successful vs. failed examples and chained multi-step edits. Apple’s pipeline uses strong multimodal models to generate and validate diverse edit examples, while deliberately including “failure” cases (preference pairs) so models can learn what not to do.
This design supports supervised fine-tuning, reward-model training, and iterative multi-step learning — all critical for more controllable and reliable image editing systems.
Expected outcome: more robust, controllable image editing models
With a richer, realism-focused dataset as a training bedrock, future image-editing models are likely to become both more photorealistic and more controllable. Engineers can fine-tune models for nuanced color correction, accurate object removal/addition, and reliable style transfer. For end users and app developers, that means smarter auto-edit features, fewer artifacts, and tools that better understand complex, chained edit instructions.
Future Impact
Better tools for creators and everyday users
Pico-Banana-400K promises to accelerate a new generation of AI-driven image-editing tools. Content creators, graphic designers, and digital marketers can expect faster, more reliable workflows—think accurate object removal, context-aware background replacements, and one-click style transfers that preserve photorealism.
For end users, these advances will filter down into consumer apps and smartphones as smarter auto-edit features, fewer visual artifacts, and intuitive text-to-edit controls that make complex design tasks accessible to non-experts.
A more competitive and innovative ecosystem
Apple’s dataset release raises the bar for other players—Google, Adobe, and smaller startups are already pushing in the same space with products like Gemini and Firefly.
By making high-quality, real-image training data available for research, Pico-Banana-400K can spark faster innovation across the industry, encouraging rivals to improve model robustness, reduce domain-shift errors, and invest in responsible model evaluation.
Broader benefits for research and productization
Because the dataset includes preference pairs and multi-step edit sequences, researchers will be better equipped to train reward models and iterative editing pipelines.
That technical progress shortens the gap between lab demos and production-ready features: models trained on realistic edits generalize better in the wild, enabling safer, more controllable commercial tools—provided licensing and ethics are managed appropriately.
A Simple Thoughts
In short, Pico-Banana-400K could be a catalytic resource that not only improves photorealistic edits and multi-step editing workflows but also democratizes advanced creative capabilities—bringing pro-level image editing to everyday users while fuelling a more competitive, innovation-driven AI graphics ecosystem.
Final Conclusion
Pico-Banana-400K is a rigorously curated, photorealistic dataset that opens new horizons for text-guided image-editing research. By providing hundreds of thousands of real image → instruction → edited-output triplets—including diverse edit types, preference pairs, and multi-step sequences—the dataset helps AI models learn more complex, realistic, and controllable edits than was possible with earlier synthetic collections.
Models trained on Pico-Banana-400K are likely to power the next generation of image-editing technology: from higher-fidelity photorealistic transformations to more reliable, multi-step editing pipelines used in consumer apps and professional creative tools. Apple’s release signals a deeper commitment to AI research and could accelerate broader improvements across industry players working on generative image tools.
Pico-Banana-400K may be the turning point for real-world, text-guided image editing—supercharging photorealistic edits and multi-step workflows across creative apps.
Sources: Apple (press release / research paper), MacRumors, AppleInsider, the Pico-Banana-400K GitHub repository, and Geekflare. (Direct article links and publication dates were consulted.)
FAQs About Apple’s Pico-Banana-400K Dataset
1. How does Pico-Banana-400K improve text-guided image editing models?
The dataset includes over 400,000 diverse editing examples, covering everything from color correction and object removal to background replacement and artistic transformations.
Because it also contains successful vs. failed edits (preference pairs), AI models can learn what good editing looks like — improving reward modeling, fine-tuning, and multi-step edit accuracy.
2. Who can benefit from using the Pico-Banana-400K dataset?
This dataset is perfect for AI researchers, machine learning engineers, computer vision teams, and creative app developers. It’s a non-commercial, research-only dataset, ideal for academic studies, open-source projects, and internal prototyping.
Developers working on AI-powered photo editors, creative suites, and visual automation tools can also use it to train smarter, more context-aware models.
3. Why is real-image data crucial for improving AI-generated photo edits?
Synthetic datasets often fail to represent real-world lighting, object textures, and environmental variation — causing AI models to produce unrealistic edits. By using real photographs, Pico-Banana-400K reduces domain-shift errors, enabling more natural, context-aware, and photorealistic AI outputs. This is critical for making AI editing tools reliable and production-ready.
4. How could Pico-Banana-400K impact the future of creative and visual AI tools?
By offering large-scale, high-quality edit examples, Pico-Banana-400K lays the foundation for next-gen AI photo editing apps. Content creators, designers, and digital marketers will soon use AI-powered tools that can follow text commands — “add sunset lighting” or “remove background” — with near-human precision. It could redefine AI-driven sustainable efficiency, creativity, photo editing automation, and visual content generation.
5. Can Apple’s Pico-Banana-400K dataset be used commercially?
No. Apple released Pico-Banana-400K strictly for non-commercial research use like the previous Nano Banana update’s. It can be freely used for educational projects, AI model evaluation, or academic research, but direct commercial use — like training paid software or AI products — requires additional licensing. However, the dataset may inspire future commercial-grade AI tools from Apple or its ecosystem partners.



